Integrating Apache Polaris with PuppyGraph for Real-time Graph Analysis
Unified data governance has become a hot topic over the last few years. As AI and other data-hungry use cases infiltrate the market, the need for a comprehensive data catalog solution with governance in mind has become critical. Apache Polaris has found its calling as an open-source solution, specifically built to handle data governed by Apache Iceberg, that is changing the way we manage and access data across various clouds, formats, and platforms. With a foundation rooted in Apache Iceberg, Apache Polaris ensures compatibility with various compute engines and data formats, making it an ideal choice for organizations focused on scalable, open data architectures.
The beauty of such catalog technologies is their interoperability with other technologies that can leverage their data. PuppyGraph, the first graph compute engine to integrate with Apache Polaris natively, is part of this revolution of making data (and graph analytics) more accessible - all without a separate specialized graph database. By working with the Apache Polaris team, PuppyGraph’s integration with the Apache Polaris is a significant leap forward in graph compute technology, offering a unique and powerful approach to exploring and analyzing data within Apache Polaris.
As the first graph query engine to natively integrate with Apache Polaris, PuppyGraph offers a unique approach to querying the data within an Apache Polaris instance: through graph. Although SQL querying will remain a staple for many developers, graph queries offer organizations a way to explore their interconnected data in unique and new ways that SQL-based querying cannot handle efficiently. This blog will explore the power of pairing Apache Polaris with graph analytics capabilities using PuppyGraph’s zero-ETL graph query engine. Let’s start by looking a bit closer at the inner workings of the Apache Polaris.
What is Apache Polaris?🔗
Apache Polaris is an open-source, interoperable catalog for Apache Iceberg. It offers a centralized governance solution for data across various cloud platforms, formats, and compute engines. For users, it provides fine-grained access controls to secure data handling, simplifies data discovery, and fosters collaboration by managing structured and unstructured data, machine learning models, and files.

A significant component of Apache Polaris is its commitment to open accessibility and regulatory compliance. By supporting major data protection and privacy frameworks like GDPR, CCPA, and HIPAA, Apache Polaris helps organizations meet critical regulatory standards. This focus on compliance and secure data governance reduces risk while fostering greater confidence in how data is stored, accessed, and analyzed.
Key Features & Benefits🔗
Apache Polaris offers several key features and benefits that users should know. Diving a bit deeper, based on the image above, here are some noteworthy benefits:
Cross-Engine Read and Write🔗
Apache Polaris leverages Apache Iceberg’s open-source REST protocol, enabling multiple engines to read and write data seamlessly. This interoperability extends to popular engines like PuppyGraph, Apache Flink, Apache Spark, Trino, and many others, ensuring flexibility and choice for users.
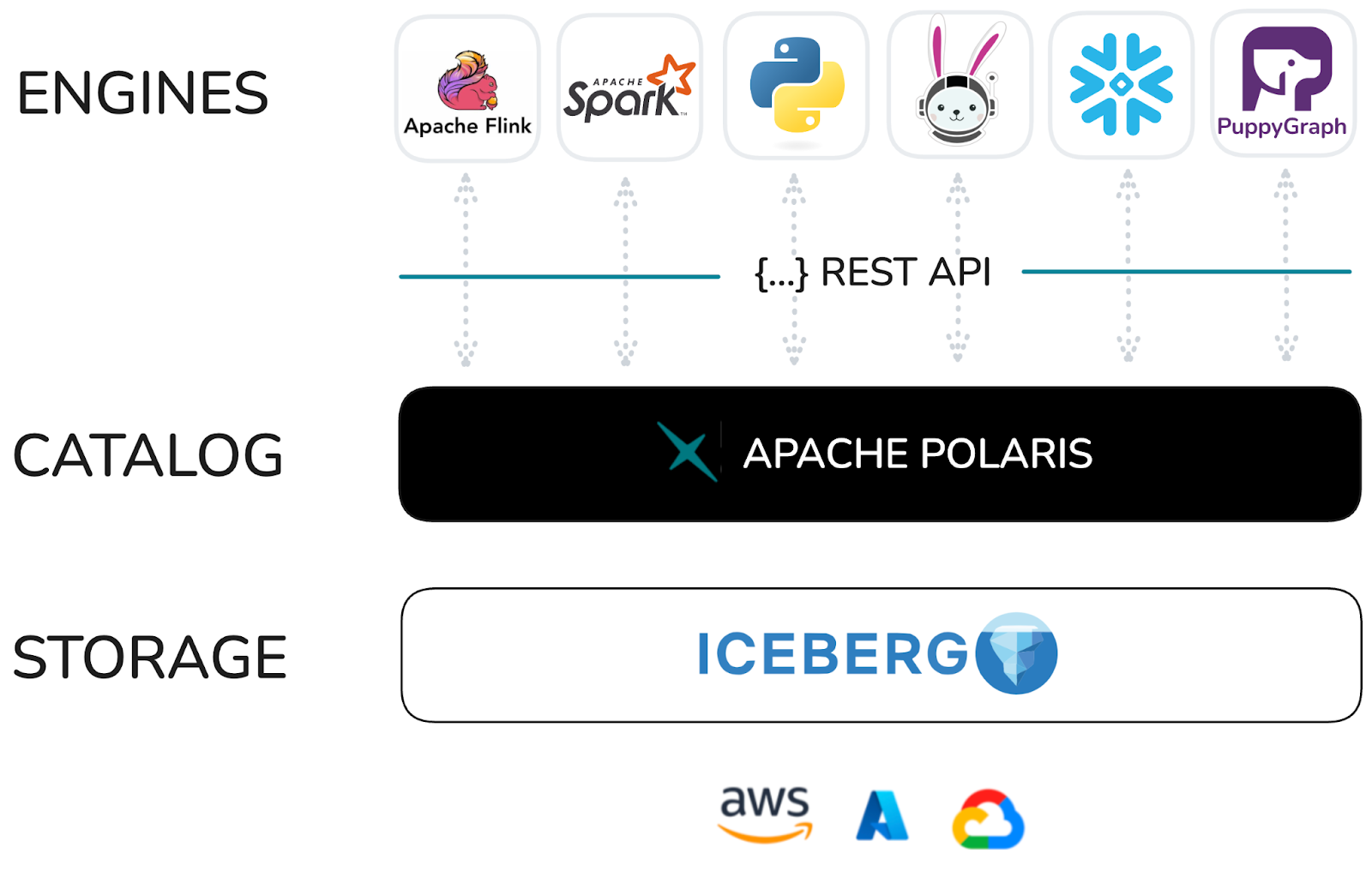
Centralized Security and Access🔗
With Apache Polaris, you can define principals/users and roles, and manage RBAC (Role-Based Access Controls) on Iceberg tables for these users or roles. This centralized security management approach streamlines access control and simplifies data governance.
Run Anywhere, No Lock-In🔗
Apache Polaris offers deployment flexibility, allowing you to run it in your own infrastructure within a container (e.g., Docker, Kubernetes) or as a managed service on Snowflake. This adaptability ensures you can retain RBAC, namespaces, and table definitions even if you switch infrastructure, providing long-term flexibility and cost optimization.
The Apache Polaris offers various ways to query, analyze, and integrate data, one of the most flexible and scalable options for organizations to store and govern data effectively.
Why Add Graph Capabilities to Apache Polaris?🔗
While SQL querying is a mainstay for most developers dealing with data and traditional SQL queries are highly effective for many data operations, they can fall short when working with highly interconnected data. Specific use cases lend themselves to graph querying, such as:
- Social Network Analysis: Understanding relationships between people, groups, and organizations.
- Fraud Detection: Identifying patterns and anomalies in financial transactions or online activities.
- Knowledge Graphs: Representing and querying complex networks of interconnected concepts and entities.
- Recommendation Engines: Suggesting products, services, or content based on user preferences and relationships.
- Network and IT Infrastructure Analysis: Modeling and analyzing network topologies, dependencies, and performance.
Enhancing Apache Polaris with a graph query engine introduces advanced graph analytics, making it easier and more intuitive to handle complex, relationship-based queries like the ones mentioned above. Here’s why integrating graph capabilities benefits querying in Apache Polaris:
- Enhanced Data Relationships: Graph queries are designed to uncover complex patterns within data, making them particularly useful for exploring multi-level relationships or hierarchies that can be cumbersome to analyze with SQL.
- Performance: When traversing extensive relationships, graph queries are often faster than SQL, especially for deep link analysis, as graph databases are optimized for this type of network traversal.
- Flexibility: Graph databases allow for a more intuitive approach to modeling interconnected data, avoiding the need for complex
JOINoperations common in SQL queries. Nodes and edges in graph models naturally represent connections, simplifying queries for relationship-based data. - Advanced Analytics: Graph platforms support advanced analytics, such as community detection, shortest path calculations, and centrality measures. Many of these algorithms are built into graph platforms, making them more accessible and efficient than implementing such analytics manually in SQL.
Users gain deeper insights, faster query performance, and simpler ways to handle complex data structures by adding the capability to perform graph-based querying and analytics within Apache Polaris. When adding these capabilities, PuppyGraph’s zero-ETL graph query engine integrates seamlessly with Apache Polaris, making it easy and fast to unlock these advantages. Let’s look at how seamlessly the two platforms fit together architecturally.
Apache Polaris + PuppyGraph Architecture🔗
Traditionally, enabling graph querying and analytics on organizational data required replicating data into a separate graph database before running queries. This complex process involved multiple technologies, teams, and a significant timeline. Generally, the most cumbersome part of the equation was the struggling of ETL to get the data transformed into a graph-compatible format and actually loaded into the database. Because of this, implementing graph analytics on data stored in SQL-based systems has historically been challenging, so graph analysis was often viewed as a niche technology—valuable but costly to implement.
PuppyGraph overcomes these limitations by offering a novel approach: adding graph capabilities without needing a dedicated graph database. Removing the graph database from the equation shortens the implementation timeline, reducing both time-to-market and overall costs. With PuppyGraph’s Zero-ETL graph query engine, users can connect directly to the data source, enabling graph queries directly on an Apache Polaris instance while maintaining fine-grained governance and lineage.
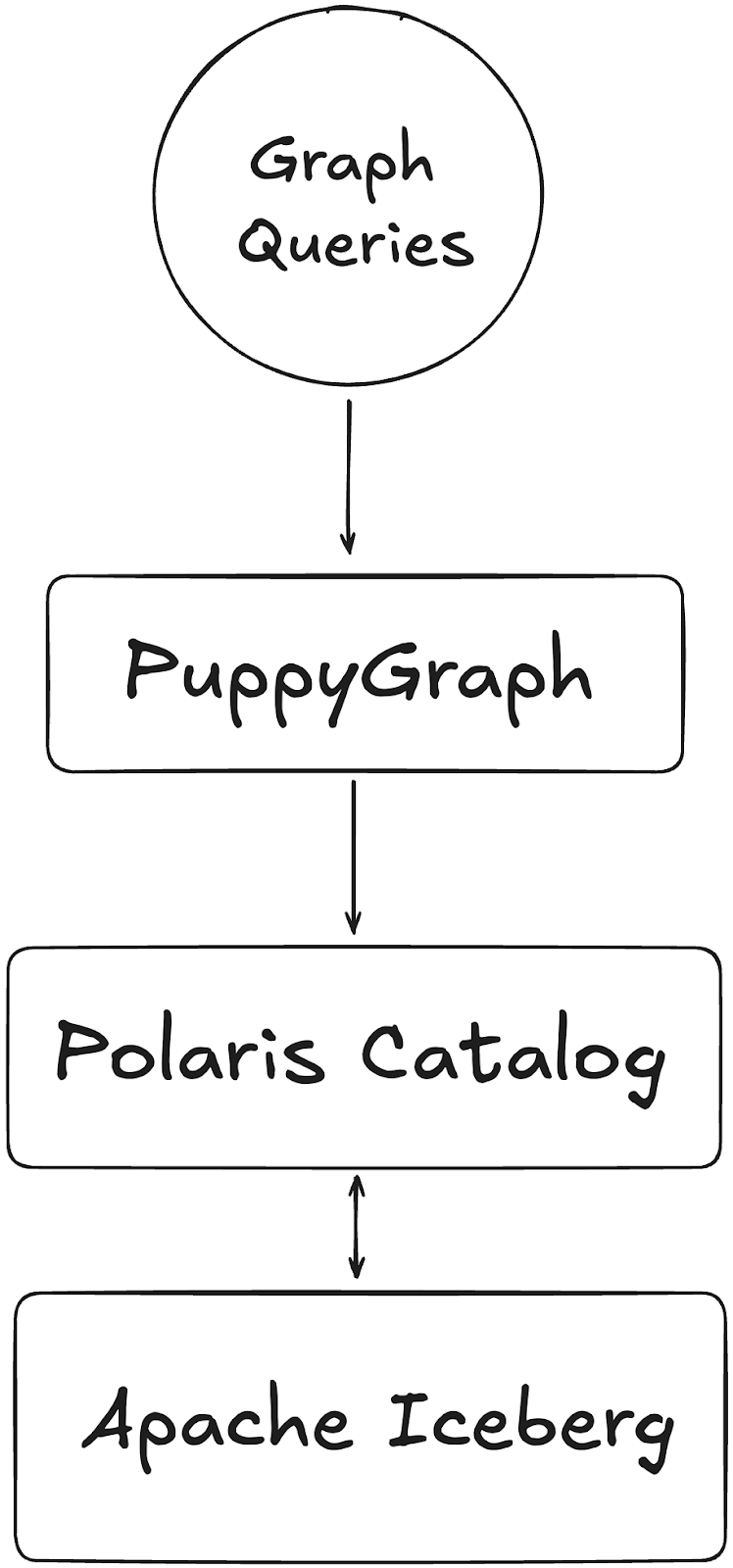
This approach allows for performant graph querying, such as supporting 10-hop neighbor queries across half a billion edges in 2.26 seconds through scalable and performant zero-ETL. PuppyGraph achieves this by leveraging the column-based data file format coupled with massively parallel processing and vectorized evaluation technology built into the PuppyGraph engine. This distributed compute engine design ensures fast query execution even without efficient indexing and caching, delivering a performant and efficient graph querying and analytics experience without the hassles of the traditional graph infrastructure.
To prove just how easy it is, let’s look at how you can connect PuppyGraph to the data you have stored in Apache Polaris.
Connecting PuppyGraph to Apache Polaris🔗
Enabling graph capabilities on your underlying data is extremely simple with PuppyGraph. We like to summarize it into three steps: deploy, connect, and query. Many users can be up and running in a matter of minutes. We’ll walk through the steps below to show how easy it is.
Deploy Apache Polaris🔗
Check out the code from the Apache Polaris repository.
1git clone https://github.com/apache/polaris.git
Build and run an Apache Polaris server. Note that JDK 21 is required to build and run the Apache Polaris.
1cd polaris
2./gradlew run
Then use the provided spark shell to create a data catalog and prepare data. Start a different shell and run the following command in the polaris directory:
1./regtests/run_spark_sql.sh
The command will download Spark and start a Spark SQL shell. Run the following command to generate a new database and several tables in this newly created catalog.
1CREATE DATABASE IF NOT EXISTS modern;
2
3CREATE TABLE modern.person (id string, name string, age int) USING iceberg;
4INSERT INTO modern.person VALUES
5 ('v1', 'marko', 29),
6 ('v2', 'vadas', 27),
7 ('v4', 'josh', 32),
8 ('v6', 'peter', 35);
9
10CREATE TABLE modern.software (id string, name string, lang string) USING iceberg;
11INSERT INTO modern.software VALUES
12 ('v3', 'lop', 'java'),
13 ('v5', 'ripple', 'java');
14
15CREATE TABLE modern.created (id string, from_id string, to_id string, weight double) USING iceberg;
16INSERT INTO modern.created VALUES
17 ('e9', 'v1', 'v3', 0.4),
18 ('e10', 'v4', 'v5', 1.0),
19 ('e11', 'v4', 'v3', 0.4),
20 ('e12', 'v6', 'v3', 0.2);
21
22CREATE TABLE modern.knows (id string, from_id string, to_id string, weight double) USING iceberg;
23INSERT INTO modern.knows VALUES
24 ('e7', 'v1', 'v2', 0.5),
25 ('e8', 'v1', 'v4', 1.0);
Deploy PuppyGraph🔗
Then you’ll need to deploy PuppyGraph. Luckily, this is easy and can currently be done through Docker (see Docs) or an AWS AMI through AWS Marketplace. The AMI approach requires a few clicks and will deploy your instance on the infrastructure of your choice. Below, we will focus on what it takes to launch a PuppyGraph instance on Docker.
With Docker installed, you can run the following command in your terminal:
1docker run -p 8081:8081 -p 8183:8182 -p 7687:7687 -v /tmp/polaris:/tmp/polaris --name puppy --rm -itd puppygraph/puppygraph:stable
This will spin up a PuppyGraph instance on your local machine (or on a cloud or bare metal server if that’s where you want to deploy it). Next, you can go to localhost:8081 or the URL on which you launched the instance. This will show you the PuppyGraph login screen:
After logging in with the default credentials (username: “puppygraph” and default password: “puppygraph123”) you’ll enter the application itself. At this point, our instance is ready to go and we can proceed with connecting to the underlying data stored in Apache Polaris.
Connect to Your Data Source and Define Your Schema🔗
Next, we must connect to our data source to run graph queries against it. Users have a choice of how they would like to go about this. Firstly, you could use a JSON schema document to define your connectivity parameters and data mapping. As an example, here is what one of these schemas might look like:
1{
2 "catalogs": [
3 {
4 "name": "test",
5 "type": "iceberg",
6 "metastore": {
7 "type": "rest",
8 "uri": "http://172.17.0.1:8181/api/catalog",
9 "warehouse": "manual_spark",
10 "credential": "root:s3cr3t",
11 "scope": "PRINCIPAL_ROLE:ALL"
12 }
13 }
14 ],
15 "graph": {
16 "vertices": [
17 {
18 "label": "person",
19 "oneToOne": {
20 "tableSource": {
21 "catalog": "test",
22 "schema": "modern",
23 "table": "person"
24 },
25 "id": {
26 "fields": [
27 {
28 "type": "String",
29 "field": "id",
30 "alias": "id"
31 }
32 ]
33 },
34 "attributes": [
35 {
36 "type": "String",
37 "field": "name",
38 "alias": "name"
39 },
40 {
41 "type": "Int",
42 "field": "age",
43 "alias": "age"
44 }
45 ]
46 }
47 },
48 {
49 "label": "software",
50 "oneToOne": {
51 "tableSource": {
52 "catalog": "test",
53 "schema": "modern",
54 "table": "software"
55 },
56 "id": {
57 "fields": [
58 {
59 "type": "String",
60 "field": "id",
61 "alias": "id"
62 }
63 ]
64 },
65 "attributes": [
66 {
67 "type": "String",
68 "field": "name",
69 "alias": "name"
70 },
71 {
72 "type": "String",
73 "field": "lang",
74 "alias": "lang"
75 }
76 ]
77 }
78 }
79 ],
80 "edges": [
81 {
82 "label": "created",
83 "fromVertex": "person",
84 "toVertex": "software",
85 "tableSource": {
86 "catalog": "test",
87 "schema": "modern",
88 "table": "created"
89 },
90 "id": {
91 "fields": [
92 {
93 "type": "String",
94 "field": "id",
95 "alias": "id"
96 }
97 ]
98 },
99 "fromId": {
100 "fields": [
101 {
102 "type": "String",
103 "field": "from_id",
104 "alias": "from_id"
105 }
106 ]
107 },
108 "toId": {
109 "fields": [
110 {
111 "type": "String",
112 "field": "to_id",
113 "alias": "to_id"
114 }
115 ]
116 },
117 "attributes": [
118 {
119 "type": "Double",
120 "field": "weight",
121 "alias": "weight"
122 }
123 ]
124 },
125 {
126 "label": "knows",
127 "fromVertex": "person",
128 "toVertex": "person",
129 "tableSource": {
130 "catalog": "test",
131 "schema": "modern",
132 "table": "knows"
133 },
134 "id": {
135 "fields": [
136 {
137 "type": "String",
138 "field": "id",
139 "alias": "id"
140 }
141 ]
142 },
143 "fromId": {
144 "fields": [
145 {
146 "type": "String",
147 "field": "from_id",
148 "alias": "from_id"
149 }
150 ]
151 },
152 "toId": {
153 "fields": [
154 {
155 "type": "String",
156 "field": "to_id",
157 "alias": "to_id"
158 }
159 ]
160 },
161 "attributes": [
162 {
163 "type": "Double",
164 "field": "weight",
165 "alias": "weight"
166 }
167 ]
168 }
169 ]
170 }
171}
In the example, you can see the data store details under the catalogs section. This is all that is needed to connect to the Apache Polaris instance. Underneath the catalogs section, you’ll notice that we have defined the nodes and edges and where the data comes from. This tells PuppyGraph how to map the SQL data into the graph hosted within PuppyGraph. This can then be uploaded to PuppyGraph, and you’ll be ready to query!
 To create the schema in this way, just save the schema to a JSON file, modify the uri and credential to reflect the actual Polaris uri and credential, and select “Upload Graph Schema JSON” to upload the JSON file. The graph will then be created.
To create the schema in this way, just save the schema to a JSON file, modify the uri and credential to reflect the actual Polaris uri and credential, and select “Upload Graph Schema JSON” to upload the JSON file. The graph will then be created.
Alternatively, for those who want a more UI-based approach, PuppyGraph also offers a schema builder that allows users to use a drag-and-drop editor to build their schema. In an example similar to the one above, here is what the UI flow looks like with the schema built this way.
Click on “Create graph schema” on the Web UI instead.
First, you would add in the details about your Apache Polaris Catalog data source:
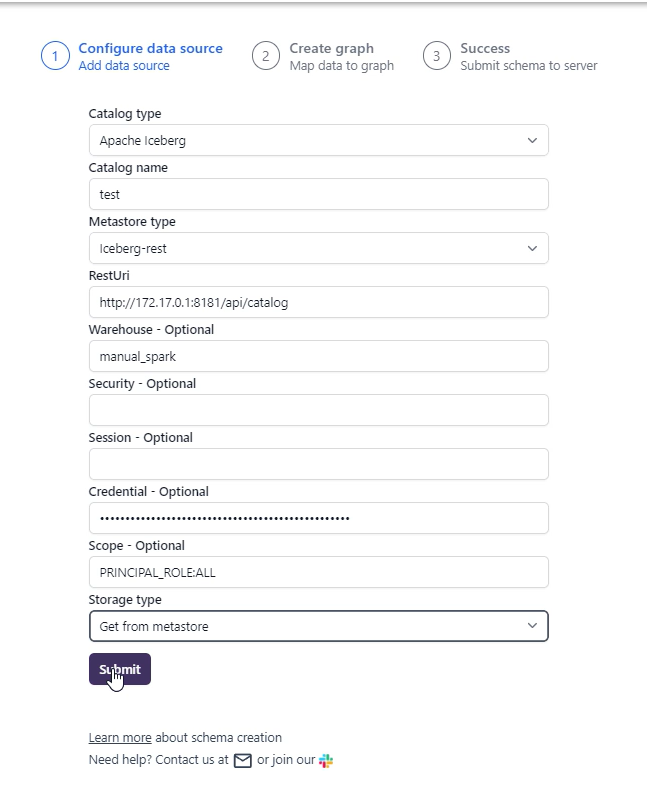
Here are the detailed explanations of the fields:
- Catalog type:
Apache Iceberg - Catalog name: Some name for the catalog as you like.
- Metastore Type:
Iceberg-Rest - RestUri:
http://host.docker.internal:8181/api/catalog. On Linux the IP for the host might be172.17.0.1if you do not add--add-host=host.docker.internal:host-gatewayto the docker run command. - Warehouse:
manual_spark. This was created by therun_spark_sql.shscript. - Credential: Fill in the root principal credentials from the Apache Polaris Catalog server’s output. For example
f6973789e5270e5d:dce8e8e53d8f770eb9804f22de923645. - Scope:
PRINCIPAL_ROLE:ALL - Storage type:
Get from metastore
Then, with the data source added, you can begin to build out the nodes and edges for the schema using the UI. PuppyGraph will allow you to easily create these by prepopulating the dropdowns based on the table data it retrieves from your Iceberg instance.
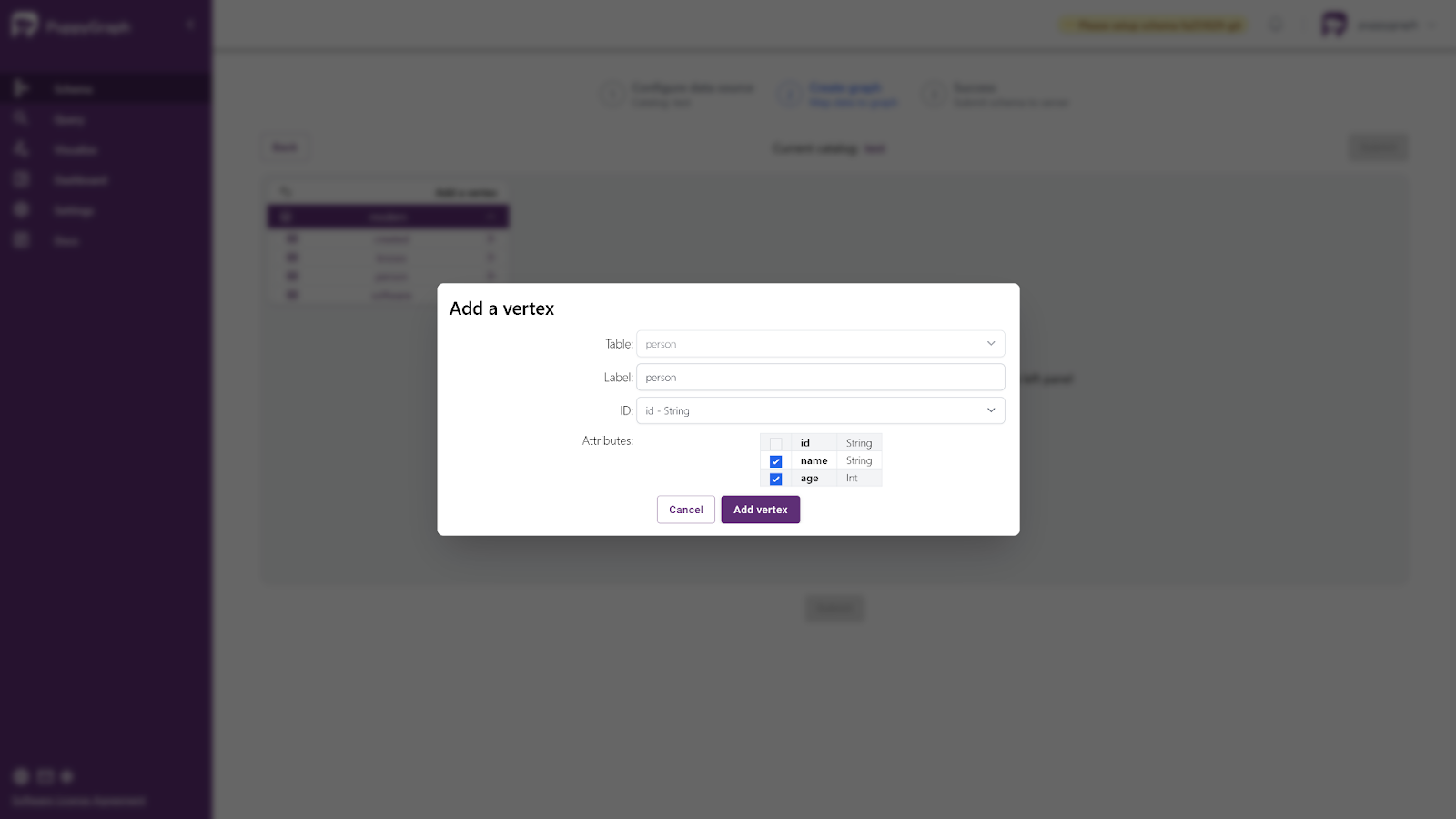
After that use the Auto Suggestion to create other nodes and edges. Select person as the start vertex (node) and add the auto suggested nodes and edges.
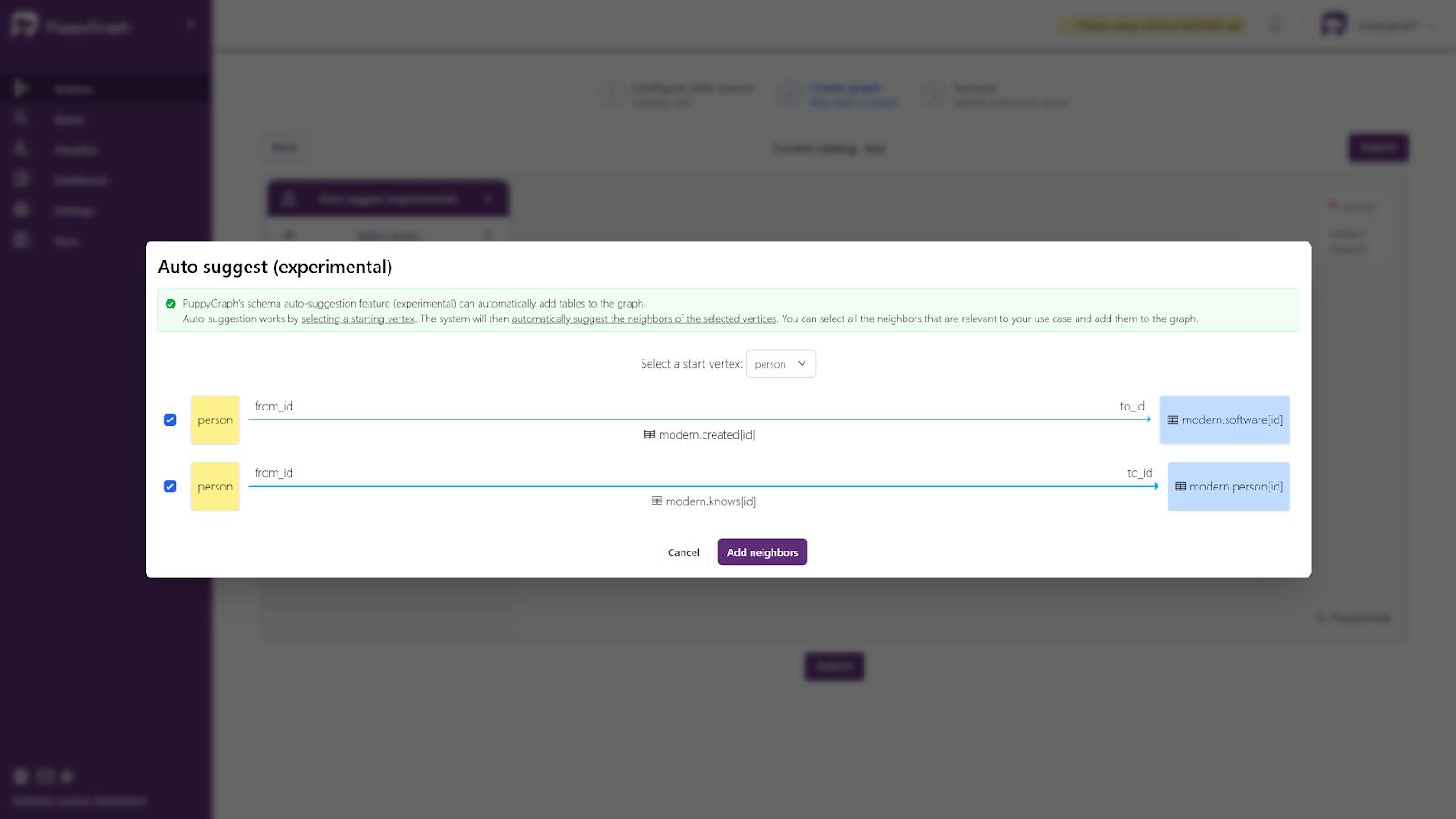
After clicking on “Add neighbors”, you’ll see it rendered on the screen as nodes and edges are added. It should look like this: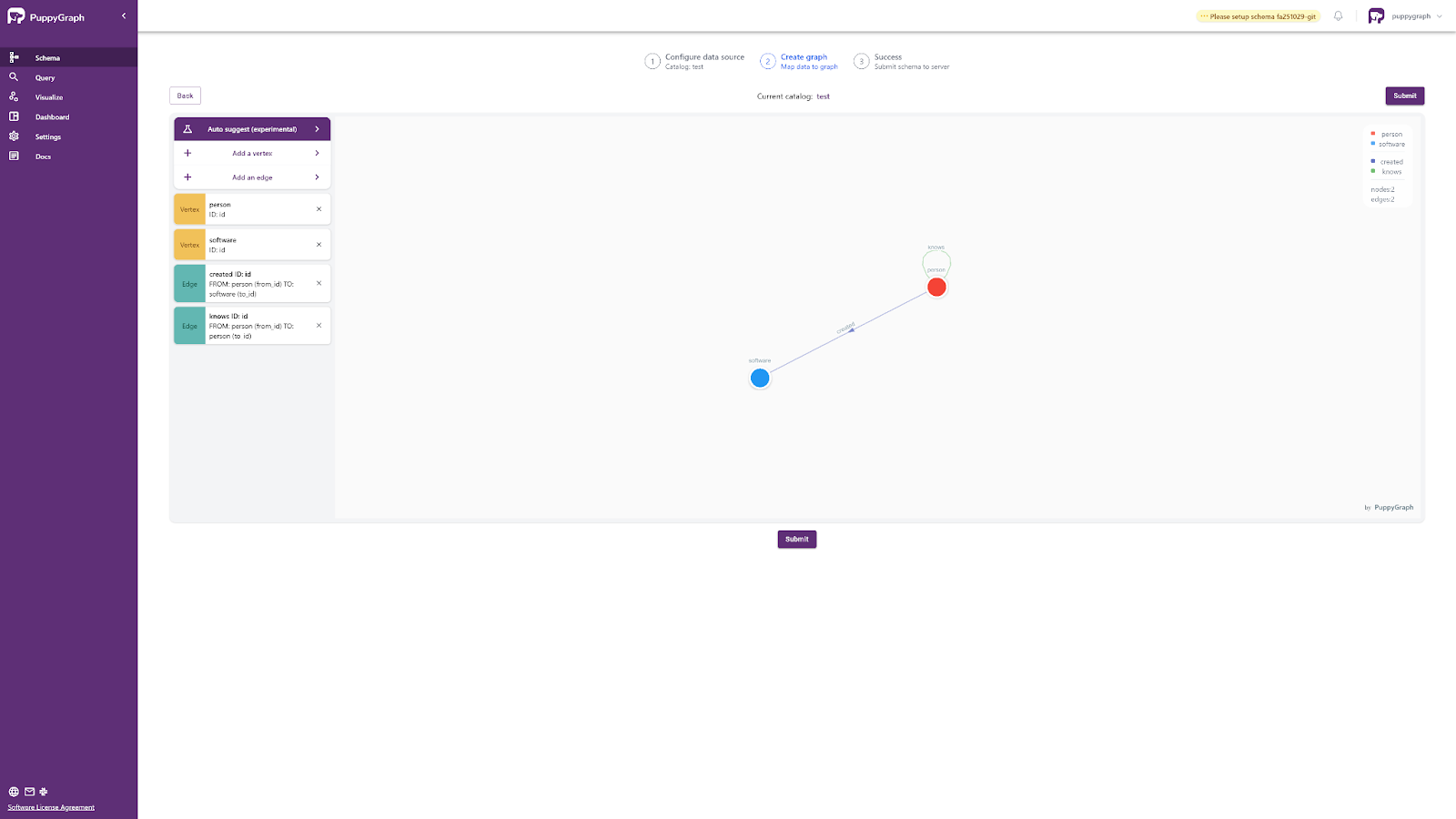
You can click the Submit button to submit the schema to the server when it is complete.
After this, your integration and schema creation are complete. That’s all that there is to it. Next step: graph querying!
Query your Data as a Graph🔗
Now, you can query your data as a graph without needing data replication or ETL. Our next step is to figure out how we want to query our data and what insights we want to gather from it.
PuppyGraph allows users to use Gremlin, Cypher, or Jupyter Notebook.
Click on Query in the left sidebar to bring the Interactive Query UI: For example, based on the schemas above, a Gremlin query, shown in a visualized format that can be explored further, will look like this:
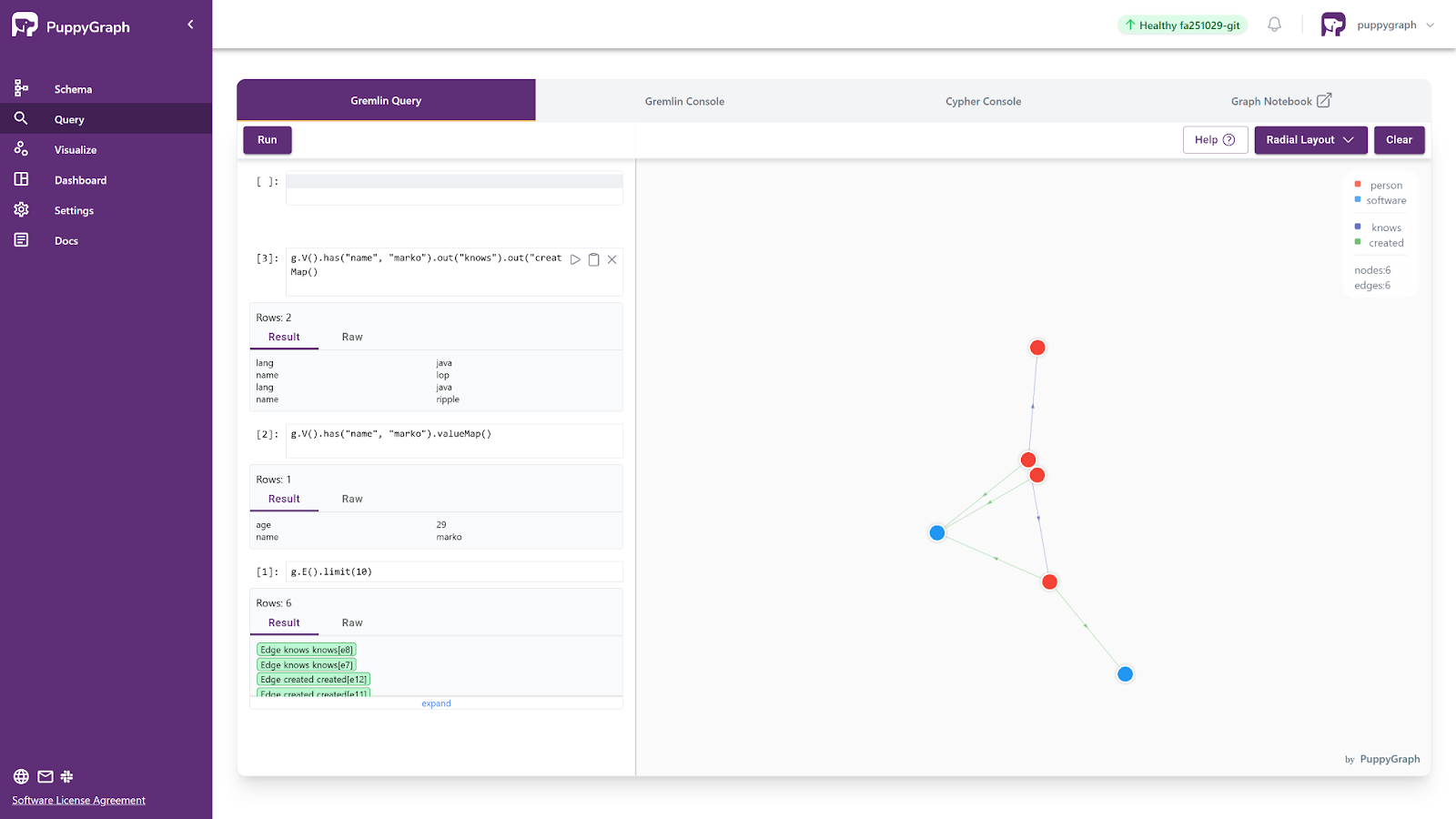
As you can see, graph capabilities can be achieved with PuppyGraph in minutes without the heavy lift usually associated with graph databases. Whether you’re a seasoned graph professional looking to expand the data you have to query as a graph or a budding graph enthusiast testing out a use case, PuppyGraph offers a performant and straightforward way to add graph querying and analytics to the data you have sitting within Apache Polaris.
Summary🔗
In this blog, we looked at how to enable real-time graph querying with PuppyGraph’s zero-ETL graph query engine and how to pair it with Apache Polaris. In a matter of minutes, we explored how PuppyGraph can be deployed and connected to your Apache Polaris instance, enabling graph queries without the overhead of traditional graph technologies.
Everything in this guide is free to try. You can download PuppyGraph’s forever-free Developer Edition and start running graph queries on your Apache Polaris instance with fine-grained governance & lineage in 10 minutes. You can also check the instructions for connecting to an Apache Polaris Catalog in PuppyGraph Documentation.